Probabilistic Automata
Have you seen those twitter bots that generate fake or parody tweets? The ones that look almost legit but are pretty much complete jibberish when you read them?
Quite often, such accounts use a so-called markov chain to generate the text. A markov chain is a state machine that has probabilistic transitions.
Examples include scigen, tiny subversions, and erikaheidi’s socialautomata.
Shannon
Here is Claude Shannon, who invented some pretty cool stuff. He’s kind of a big deal. In this picture he is most likely not giving a fuck.

Seriously though, he did some awesome shit.
In 1948 Shannon published a rather important paper in the The Bell System Technical Journal. It was titled A Mathematical Theory of Communication1.
It is considered to be the paper that laid down the foundations for the field of information theory. In the first section, Shannon talks about discrete noiseless systems and as an example of an information source for such a system, written language.
He shows a way to model a language based on the letter frequencies, by using a markov chain, which can be used to approximate, say, English. This quote should give a rough idea of how it works:
To construct [a second-order approximation] for example, one opens a book at random and selects a letter at random on the page. This letter is recorded. The book is then opened to another page and one reads until this letter is encountered. The succeeding letter is then recorded. Turning to another page this second letter is searched for and the succeeding letter recorded, etc.
The example of generated text from the second-order word approximation is:
THE HEAD AND IN FRONTAL ATTACK ON AN ENGLISH WRITER THAT THE CHARACTER OF THIS POINT IS THEREFORE ANOTHER METHOD FOR THE LETTERS THAT THE TIME OF WHO EVER TOLD THE PROBLEM FOR AN UNEXPECTED.
This mostly laid the groundwork for a lot of twitter bots.
Deterministic Finite Automaton
The deterministic state machine defines a class of computations that is not turing complete. Any regular expression can be compiled down to such a state machine.
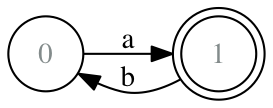
Implementing such a state machine is rather trivial, it is a foreach loop and a key lookup:
$rules = [
0 => ['a' => 1],
1 => ['b' => 0],
];
$state = 0;
$tokens = str_split('abab');
foreach ($tokens as $token) {
$state = $rules[$state][$token];
}
DFAs are mostly used for matching existing text against regular expressions.
Generating
However, with some very small extensions it is possible to make this machine generate output based on the same transition rules:
$rules = [
0 => ['a' => 1],
1 => ['b' => 0],
];
$state = 0;
$output = '';
foreach (range(1, 6) as $i) {
$tokens = array_keys($rules[$state]);
$token = $tokens[array_rand($tokens)];
$output .= $token;
$state = $rules[$state][$token];
}
Back in the days there were no random number generators yet. Thus, Shannon had to use a book of random numbers. Luckily, we have algorithms for that now.
This modified state machine will randomly pick one of the possible tokens it could transition to.
And sure enough, this example generates the sequence ababab.
Probabilities
As it stands, the machine uses array_rand, which means it will pick the next character with an equal probability for all possibilities. If we want to model full languages though, we will need to allow certain sequences to be more probable than others.
This can be done by copy-pasting a function from StackOverflow:
function weighted_pick(array $weighted_values) {
$rand = mt_rand(1, (int) array_sum($weighted_values));
foreach ($weighted_values as $key => $weight) {
$rand -= $weight;
if ($rand <= 0) {
return $key;
}
}
}
Very well, now to make this work properly, we will change the format for the transition rules a bit. The new format will be:
$rules = [
'a' => ['b' => 1, 'c' => 2],
'b' => ['a' => 1],
...
];
The states have been replaced with the characters. Merging the two concepts simplifies implementation a lot. The letter a will be followed by the letter b with a probability corresponding to the weight 1 and c with weight 2.
In other words, a will be followed by b 33% of the time and by c 66% of the time.
Building rules
With that annoying stuff out of the way, we can do something really amazing. We can dynamically build a set of transition rules, based on some input text!
This means we can feed some text to generate the rules, then produce statistically similar text from them!
As a matter of fact, we will use some tricks here:
-
For the transitions we will consider the last n characters (where n is adjustable).
-
We will also produce n characters (a unit known as n-gram) in each transition, this gives us more better words.
This produces much better results, as we will see.
$n = 4;
$rules = [];
$source = 'With that annoying stuff out of the way, we can do something really amazing. We can dynamically build a set of transition rules, based on some input text! This means we can feed some text to generate the rules, then produce statistically similar text from them!';
foreach (range($n, strlen($source)-4) as $i) {
$ngram_a = substr($source, $i - $n, $n);
$ngram_b = substr($source, $i, $n);
if (!isset($rules[$ngram_a][$ngram_b])) {
$rules[$ngram_a][$ngram_b] = 0;
}
$rules[$ngram_a][$ngram_b]++;
}
Running this example will build a set of rules that looks like this:
$rules = [
'With' => [' tha' => 1],
'ith ' => ['that' => 1],
'th t' => ['hat ' => 1],
'h th' => ['at a' => 1],
' tha' => ['t an' => 1],
'that' => [' ann' => 1],
'hat ' => ['anno' => 1],
'at a' => ['nnoy' => 1],
...
];
We can now generate random text based on these transitions:
$state = 'With';
$output = '';
foreach (range(1, 20) as $i) {
$output .= $state;
if (!isset($rules[$state])) {
// no transition found for state
break;
}
$state = weighted_pick($rules[$state]);
}
Here are some of the produced examples:
-
With that annoying stuff out of transition rules, then produce statistically ama
-
With that annoying stuff out of the way, we can do something really build a set
-
With that annoying stuff out of the way, we can feed something really amazing. W
-
With that annoying stuff out of the rules, then produce statistically build a se
These 4-grams produce english text, even for a really small input size!
Results
We can now start playing with multiple sources, mixing them and generating weird text based off of them.
I’ll go with the classic and use my own twitter feed2:
sign a CLA just to get started, and I already quite powerful that programmer: @igorwesome will talk about abstractions for me. Even with php://memory. For testing, no template engine, so much. ❤
stop this machine has gödel numbers and memory will be phpeople, because they dug it up, the current approach seems more likely has too much?"
about Design, Composition is the same as static classes. More statement followed by sinatra dependency. Also, a brain-eating any emails from your #Silex with companies to pay money.
see important part needs goto fail; goto fail; goto fail; goto fail; goto fail; goto fail; goto when you think of your choice to put in your Application/json'))
